Extracting and transforming data for access by end users and business applications is a process that has become increasingly complex. Not only are data sources growing in terms of numbers and distribution, but the diversity of data domains and formats involved have also increased dramatically. By presenting this variety of sources in a consistent, business-friendly way to end users and applications through a shared architecture, data virtualisation promises to overcome these challenges and thereby significantly improve data access and delivery at today’s data-driven organisations.
But is that really the case in the real-world? Here we look at an extreme use-case involving a Global 50 oil and gas firm that provides energy-related products and services in over 100 countries across six continents.
The Business Challenge
Such a company, as you’d expect, operates a very complicated business model involving highly diverse business processes. Beyond your typical business functions such as HR, marketing, finance, etc, the firm also performs myriad upstream exploration activities such as underwater oil well drilling, which are complex and data-driven.
In addition, the company has expanded through acquisition, so while the company’s focus is global, there are local variants to everything that it does. As a result, the firm managed to amass over 3,000 applications in its business portfolio.
Since upstream data is stored and managed in multiple systems and locations, providing diverse users such as business analysts, petroleum engineers, geologists, project managers, and more with access to data across this complex landscape in a complete and consistent manner was a huge business challenge. To address completeness, the organisation made it its mission to establish a single, logical source for all upstream data access. To address consistency, their objective was to present data to users in business-friendly views/data services that conform to a set of standard business definitions or common canonical data models, no matter where the data came from.
The Data Virtualisation Solution
To overcome these challenges, the firm chose TIBCO Data Virtualisation to implement a data virtualisation layer to support the analysis, reporting and decision-making needs of their diverse users and analytic applications. The logical architecture of the solution is shown in the diagram below:
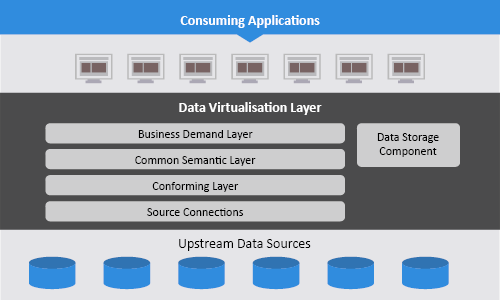
Upstream Data Sources – The firm has connected over 60 data sources (note: all of SAP is considered to be one source), representing a wide range of business functions (from well and production data to people and finance data) to the data virtualisation layer. New data sources are added regularly, without affecting consumer applications.
Data Virtualisation Layer – This is the layer where all the data landscape complexities are resolved. This layer covers almost 650 common business entities and over 9,000 attributes in order to provide consistent, business-friendly data access across multiple disparate data sources. As new data sources are added, the scope of the data access increases. But from the point of view of the data users, who do not need to know where that data is located or stored, the solution provides a consistent, single point of access to the firm’s data as and when required. This is done by ensuring that all the data that passes from the source through the data virtualisation layer is conformed to common canonical data models.
If we take a look under the hood of the data virtualisation environment, we find that the company has created a layered architecture with each layer performing a common set of functions. These include:
- Business demand layer – Publishes the views/data services that users and applications use to access the data.
- Common semantic layer – Provides a repository for views/data services that represent the 650 shared common canonical data models.
- Conforming layer – Transforms the data returned by the source connection(s) into views/data services that conform the source data to the common canonical data models.
- Source connections – Accesses the data sources and makes the source data available to the conforming layer.
- Data storage component – Enhances the performance of the data virtualisation layer by staging selected datasets for faster retrieval.
Consuming applications – The data virtualisation layer is currently used by over 40 analytical applications for a wide range of business processes, with query volumes reaching as high as 60,000 queries per day. Whenever the company seeks new insights or adds new analytic applications, they can do so without having to worry about complete and consistent data access.
Benefit Realisation
Once the data virtualisation system was up and running, in addition to meeting its initial data consistency and completeness goals, the company achieved additional significant benefits.
Reduced risk through better decisions – Data virtualisation dramatically improved the company’s overall decision-making process by providing a faster and more cost-effective way of providing users with integrated, high-quality data. This significantly reduced operational risk.
It opens up new opportunities to increase revenue and reduce costs – Integration of key data across the firm’s global operations made it easier to identify and act on opportunities that increase revenue and/or reduce costs. For example, having the right data helps them make better decisions on where to drill new oil wells, while more up-to-date, integrated project progress reporting gives the company better control and reduce spending on high-cost projects.
Enhanced business agility and competitiveness – The improved efficiency and resource allocation provided by data virtualisation has given the firm the ability to do things faster and smarter, and thereby gain an edge over their competition. By automating data access and delivery, users and IT staff are now able to redirect their time on additional value-add activities.
Improved IT performance equals lower costs – The company has also realised multiple IT benefits implementing data virtualisation including: reduced time to solution for meeting new business requirements; much lower total-cost-of-ownership than previous data access approaches; greater analytic tool flexibility due to decoupling of data access and consumers; and a simpler, more agile data architecture in total.
Overall, TIBCO Data Virtualisation has truly benefited the company in terms of reducing complexity and cost and providing faster, easier, more complete and consistent access to upstream data. Furthermore, support for data virtualisation has grown steadily beyond the original users in the upstream business. And while the organization was one of the earliest adopters of the data virtualisation approach, many users are wondering “Why didn’t we use it sooner?”
For more on TIBCO and how data virtualisation can help improve your business, click here.